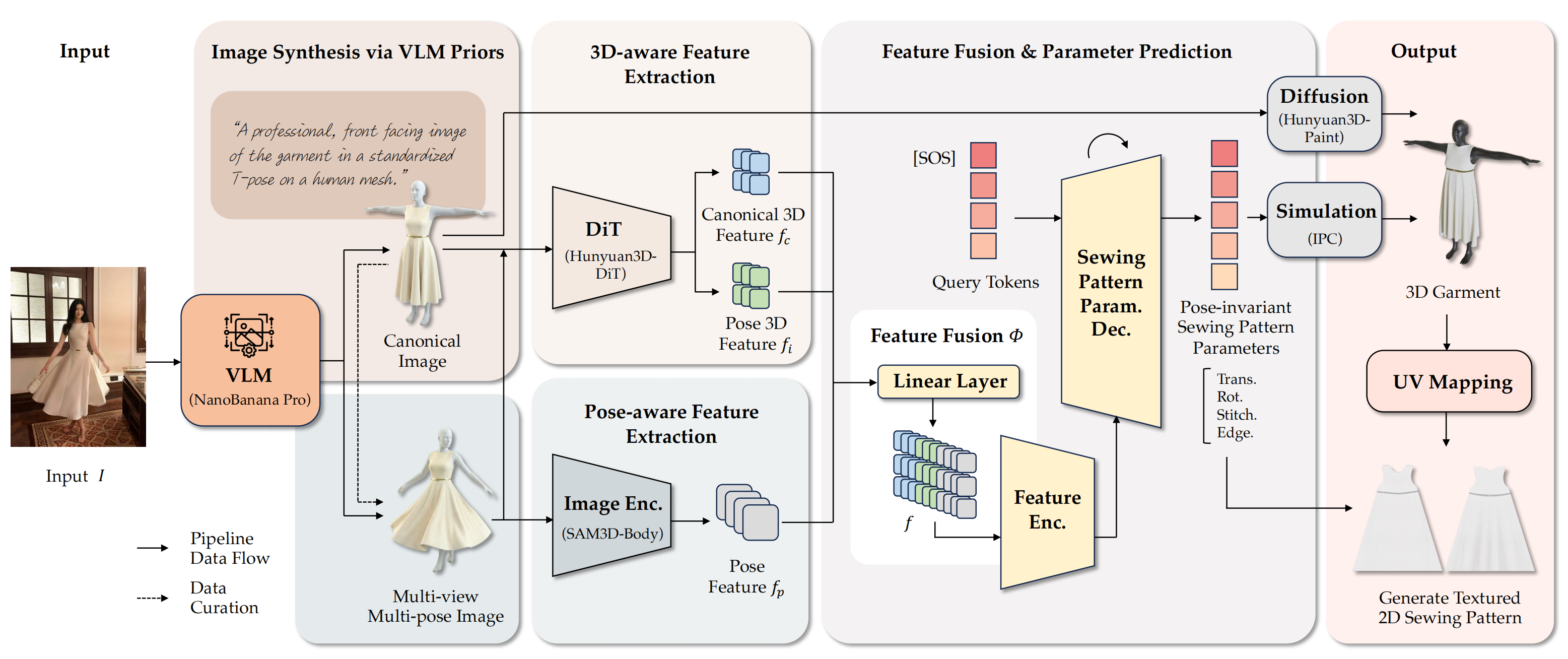
Given an in-the-wild image, DressWild reconstructs simulation-ready sewing patterns and a corresponding 3D garment.

We leverage the robust capabilities of VLMs to bridge the pose discrepancy and data gap between the training and inference stages. While our training dataset consists primarily of canonical frontal T-pose data, in-the-wild images exhibit diverse and unconstrained poses. To address this, we design a novel data curation paradigm. Specifically, we craft a comprehensive set of tailored prompts for pose, view, and scene editing to synthesize a large volume of multi-pose and multi-view images.

Scroll vertically to explore the full comparison figure.

















 DressWild: Feed-Forward Pose-Agnostic Garment Sewing Pattern Generation from In-the-Wild Images
DressWild: Feed-Forward Pose-Agnostic Garment Sewing Pattern Generation from In-the-Wild Images
